“Nobody ever got fired for buying AWS”

In the 1970s & 80s, the expression “nobody ever got fired for buying IBM” was coined to illustrate IBMs utter dominance of the IT industry, and how executives playing it safe kept buying IBM, despite their products frequently being more expensive and inferior to alternatives.
I believe we’ve reached the same cross-roads for todays dominant cloud provider, AWS (and to a lesser extent AWS major competitors). Why? Let me elaborate!
The TL;DR version of my argument is simple: AWS are overcharging clients for compute, bandwidth and to a lesser extent, storage, in a way that is eye-watering.
AWS operating margin in Q1 of 2022 was 35.3%, up from 29.8% the year before. Both these numbers are pretty extreme for what should be a commodotized business subject to cut-throat price-wars. It’s not uncommon for commodity markets to have margins in the mid single-digit range. Sure, AWS has clear economies of scale, which reasonably boost their margins, but 35.3% is still amazing.
That AWS is over-charging becomes all the more apparent if you shop around with smaller cloud providers and notice AWS prices might in some cases be 8X or more what others charge. Let us illustrate with an example:
Example app cost comparison
We will use a made-up example app, and compare costs of three variations: one is an AWS Serverless implementation, another using AWS Elastic Kubernetes Service with a reasonably sized cluster, and another one using a cluster with a cheap smaller provider. For this example, I’ve chosen the German provider, Hetzner Cloud, as well as Cloudflare for networking/storage/CDN. I’m not affiliated with Hetzner, but chose them, because their tag line is “Truly thrifty cloud hosting”, which seems promising for a comparison.
The App
Lets consider an eCommerce app with the following criteria:
- Receives 80mn API requests per month.
- Average request latency is 300ms (not amazing, but not awful).
- 20TB of bandwidth used, accounting for a mix of images and API requests.
- 50GB of block storage used to store images etc.
- 200GB of database storage.
- 50% of requests require a database (of some sort), 40% is read, 10% write.
Let’s move on to the example setups. All of them will be simplified - there could be less, or more that goes into
Serverless setup
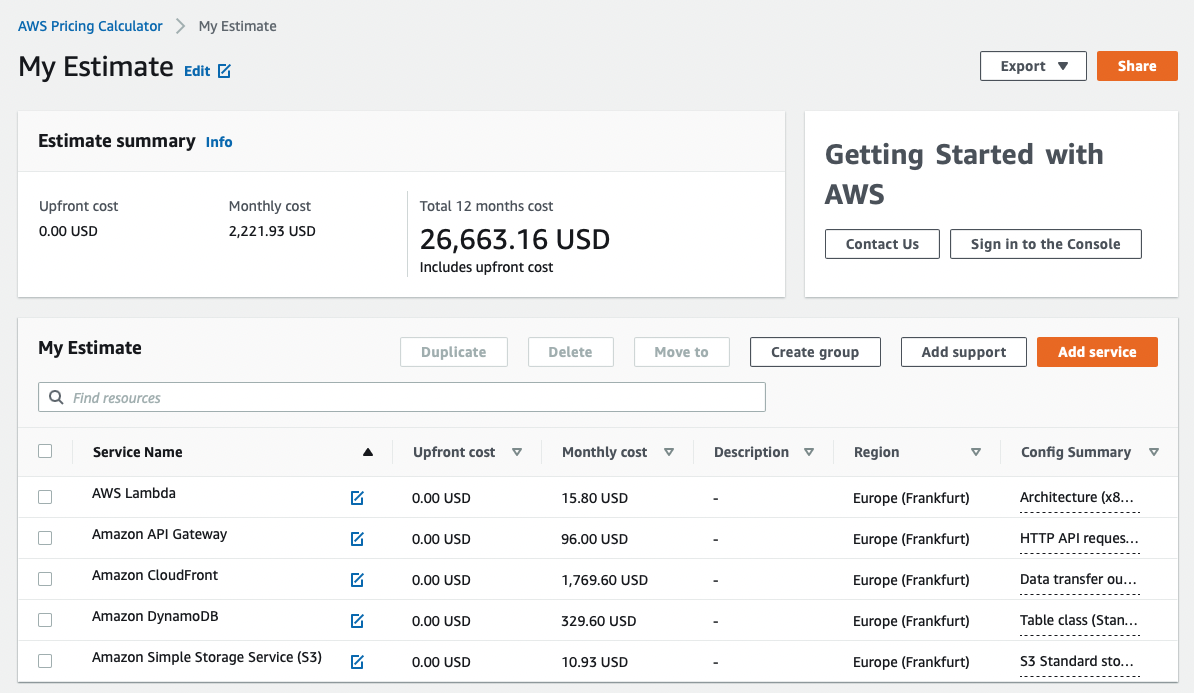
For simplicity, let’s use the following setup:
- CloudFront for CDN & passing traffic through a domain of your choice.
- API Gateway.
- Lambda with 512mb for compute.
- DynamoDB as a database, cheapest on-demand settings.
- S3 for block storage.
All set up in Frankfurt Germany. Total bill: 2221.93 USD/month (see AWS Calculator screenshot below).
AWS EKS setup
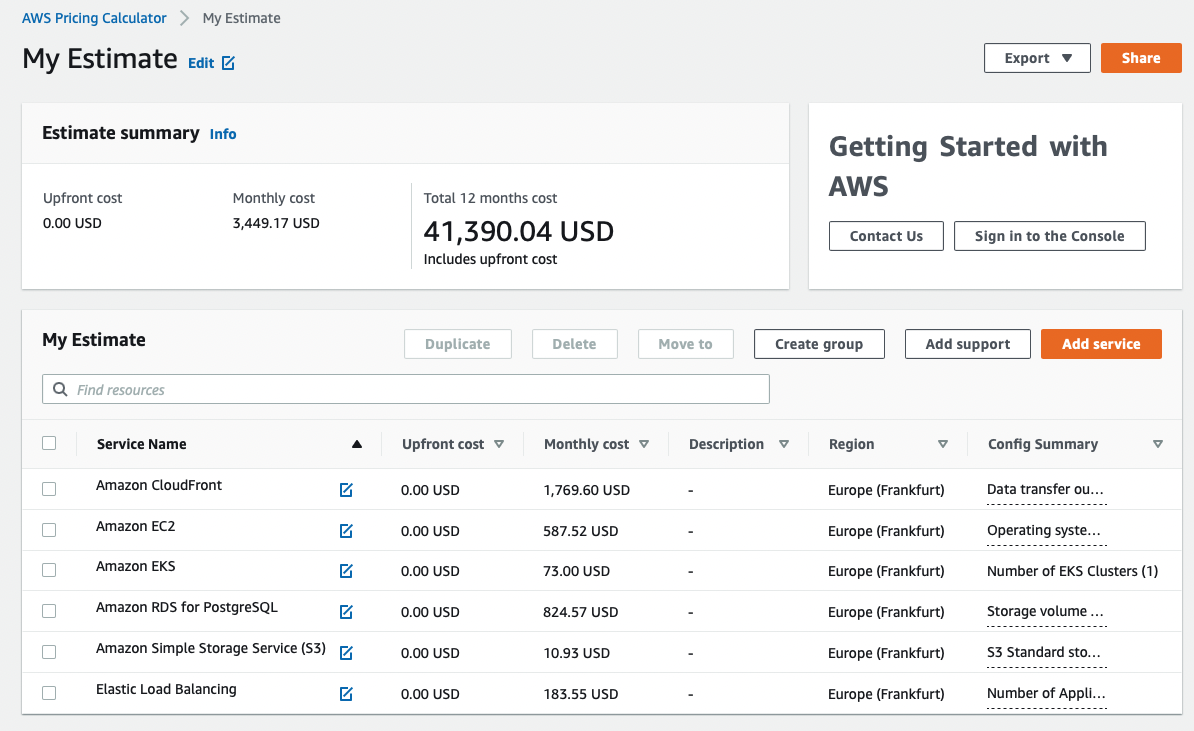
- CloudFront
- S3 for block storage
- RDS PostgreSQL as a database,
db.m3.xlarge(4vCPU, 15GB RAM), 2 nodes, single availability zone - EKS backed by 10 EC2
t3a.largenodes (2vCPU, 8GB RAM), one year reserved instance, no upfront payment - AWS Application Load Balancer as load balancer for the cluster
Total bill in Frankfurt, Germany: 3449.17 USD/month (see AWS Calculator screenshot below).
Cloudflare + Hetzner setup
We don’t have a calculator at our disposal here, so prices will be inline.
- Cloudflare for DNS, CDN & load balancing: free. Even the bandwidth is free.
- Cloudflare R2 for storage: $6
- 10x Hetzner CCx12 dedicated vCPU instances for our compute cluster (2vCPU,8GB RAM, 20TB external traffic included): 10x23.68 Eur for 236.80 Eur/month.
- 2 CCX22 cloud instances (16GB RAM, 4vCPU) for PostgreSQL, at 41.53 Eur each, total 83.06 Eur
- 2x 250GB GB Block storage volumes for databases (each replicated across 3 machines): 23.8 Eur/month.
Total bill: 343.66 Eur + 6 USD, or 355.27USD/month (at the exchange rates at the time of this being written).
Comparison and caveats
The AWS stacks are 6.25X and 9.7X more expensive than our budget stack respectively.
Of course, both stacks are gross over-simplifications of what a real system might look like. For the use-case, the server-based infrastructures may also be a little overdimensioned, I’d expect them to idle most of the time on any reasonably written software. But we can make the assumption we have the extra servers for redundancy and uptime protection.
The elephant in the room is bandwidth costs. While AWS compares unfavourably across pretty much all dimensions, the budget stack is “only” less than 50% cheaper on block storage & compute. It’s bandwidth costs where AWS really get to your wallet! We are not alone in noting this, Cloudflare is going after this hard with their Bandwidth Alliance, which is probably mostly Cloudflare spearheading a marketing attack on AWS together with other cloud providers.
A dishonourable second in usurious pricing is AWS managed database services. Yes, you get the benefit of backups, auto-restore, increased reliability etc, but.. How to set up HA databases with frequent backups and auto-restore is pretty common knowledge at this point. I suspect some keen Googling will find you one or more open source Infrastructure-as-Code Github repos that help you do this with little effort.
Using Serverless to create vendor lock-in
AWS is currently busy enticing organisations with their Serverless offerings, and enticing it is. The pitch is managed services where you don’t have to worry about availability, less need for expensive DevOps Engineers and less worrying about on-call emergencies in the middle of the night.
The truth is somewhat more nuanced: while Serverless no doubt has many benefits, and there is a nugget of truth in the claims, it still requires deep ops knowledge. It even increases the need for automation (arguably a good outcome) and automation skills (less good for those hoping to fire their DevOps Engineers). Other side effects are, that while prototyping is simple, building any system of meaningful complexity risks becoming more difficult: there is no local feedback loop. Systems have to be deployed to be meaningfully tested. You are way deep in non-standard tech.
And herein lies the rub: While AWS Serverless brings many benefits, I suspect its main strategic purpose for Amazon is to lock in cloud customers into their eco-system. Once you are on Serverless, it’s difficult to get out, unless you took proactive precautions (which is possible!).
But what about AWS reliability?
Snarky response: tell that to us-east-1 and 2 customers.
More nuanced response: yes, the sheer global footprint of AWS, and their experience in running data centres means that you could build systems where you rarely have to worry about downtime. But the sad truth is, most organizations use AWS but still don’t do this. Many organizations fail at the very basics: observability, alerting, decent code quality, good Infrastructure-as-Code practices & automation, reliable pipelines. Among those who do well, the ones that think about global deployments, or even use of multi-datacentre infrastructure are few and far between.
Another, perhaps more controversial question is: what level of reliability is financially justified?
While some might pride themselves, or even need 99.999% uptime, many businesses are probably ok with 99% or even 98%. It all depends on the cost of downtime, vs the cost of maintaining uptime. At some point infrastructure costs, engineering costs and on-call costs exceed the saved revenue for a company. This is a calculation that should be done.
Surely managed services save on people costs?
Yes, they absolutely do. And in many cases, a managed service is easier than hiring a few DevOps Engineers. However, there are a few other things to consider:
- AWS is not the only provider of managed PaaS/IaaS services.
- At scale, and probably a scale that arrives with organisations with more than 50 engineers (give or take), the infrastructure costs using AWS, Google or Azure might be so high, that the savings of using one or more cheaper providers might actually pay for the cost of a team of engineers managing the cloud infrastructure.
- Eventually, most non-small organisations have such specific needs, they need the aforementioned engineers anyway, regardless of cloud provider or managed services used.
A final note is, the move towards managed services is not purely a cloud provider/AWS play. Open Source is quickly catching up. Serverless may well be eating servers. But I would not bet against mostly self-managing Open Source Platforms as a Service (PaaS) eventually eating Serverless.
The path forward: Cloud independence & self-managing PaaSes
To conclude things, it’s worth mentioning that, we at Chaordic are big believers in Serverless, but we don’t think it’s the end of the road. Something else is coming.
The most likely scenario is where Open Source catches up. It becomes trivial to deploy your own PaaS with a few open source components. Yes, it will run on servers (just as Serverless!), but it will be self-healing and mostly self-managing, to the extent the lines to cloud provider Serverless offerings will be blurred. Most likely, we will also see some degree of cloud awareness, whereby cloud agnostic platforms can optimize where and how they run based on desired cost vs performance trade-offs.
In the meantime, AWS is a good choice, but not the only choice. It’s worth shopping around while we wait for the next shiny evolution in compute infrastructure. And even when the shopping around is done, it’s worth building your software in such a way, that moving it between clouds and runtimes is relatively pain-free. The effort that goes into this is smaller than you might think.
Cloud provider can,and do hike prices, sometimes in painful ways after they’ve lured you in.
In a world where we are moving towards a de-facto monopoly or oligopoly, price hikes are almost inevitable. Don’t become a victim of future monopolies, consider all your options.