From punch-cards to serverless - a brief history of IT operations
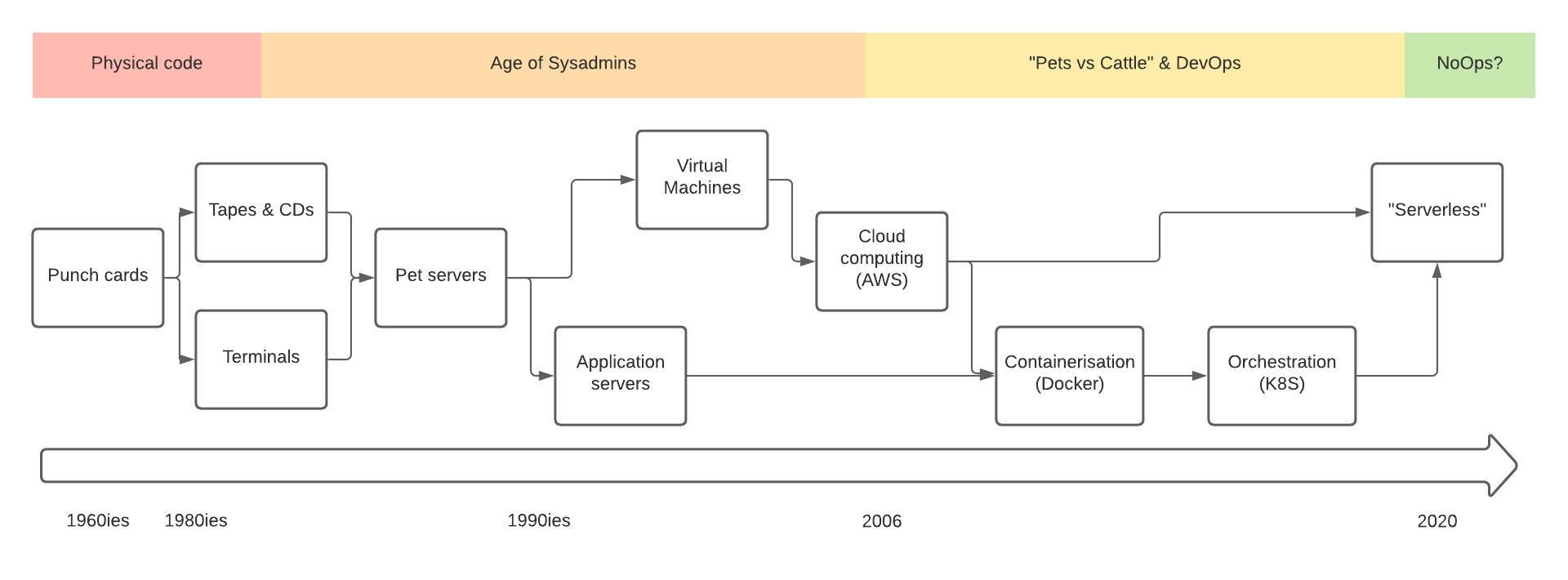
To know where we are going, it is sometimes useful to reflect on where we have been and the progress we have made. Let’s take a walk down memory-lane and see how IT operations- and software deployments have evolved and where this might lead us.
Early days - from physical code to physical mediums

In the early days of software, code was physical. Programmers wrote on coding sheets, which were then translated into punch cards. The feeding of punch cards into a mainframe had to be scheduled and made by an operator at a designated time. Output was inspected, corrected and new cards prepared, often from scratch. Eventually the output would be good enough for a supervisor to approve it for a production run.
This is a gross oversimplification of the process many places followed. But the development feedback cycle we take for granted today was unfathomable in the days of punch cards, at best counted in hours, but most often in days or weeks. Compare this to the almost instantaneous feedback developers are used to today.
The feedback cycle improved with the advent of direct entry into terminals and later software portability with physical mediums like tapes and CDs. The constraint of being able to execute code during development and testing was finally moved to the logistics of moving finished code to users.
The age of sysadmins begins
The transition from mainframes & minicomputers to a client-server model of computing occurred in the 80’s and early 90’s as PC’s and microcomputers became more affordable.
This simultaneously gave rise to the mighty Sysadmin. With this, deployments of bespoke software also went digital in the 90’s: in-house software would be compressed as tarballs, ftp’d or telnetted to the appropriate server and often installed with a pre-made install script.
In the mid- to late nineties, the move from client-server to web applications slowly started. For a brief time, the Common Gateway Interface (CGI) ruled the roost as the most convenient way to deploy web software: just upload a script into a pre-determined folder and watch it go.
The progress from the very early days of our industry were huge. Perhaps it is telling that many organisations to this day have not progressed too far from this approach in 25 years, with the ways of getting software in front of people recognisable for a presumptive time-traveller.
The great leap forward made in this era was breaking the constraint and complexity of getting new software in front of end-users: the logistics now firmly lived with the sysadmins and the software organisations themselves. Managing servers and software deployments was now the constraining factor, not shipping CDs to end users.
Of course client-server architectures still live on, and have made a reappearance with the advent of smartphones, but their overall importance to corporate IT has continuously vaned since the mid- to late nineties.
Application servers - a failed “proto-Kubernetes”
The late 90’s gave rise to the application server, with J2EE likely being the most famous example.
The thesis was that providing a standardised packaging format, combined with standard deployment platform (the application server) that could be clustered, the underlying infrastructure could be abstracted away. To the observant, this might sound a lot like Docker & Kubernetes of today.
While diagnosis of the underlying problem was mostly correct, unfortunately for application servers, the execution was found wanting. Firstly, the ambition to automate was not great enough: the process was assumed to be standardised, but made no assumptions of wide-scale automation. Secondly, application servers themselves were often cumbersome to install & operate, as anyone trying to run Websphere on a laptop in the early 2000s is likely to attest to. Thirdly, several building blocks required to reap economic benefits were still missing.
Like many things that once came out of Sun Microsystems, the application server concept had many good, maybe even visionary ideas, but the time was simply not right. It was too early, too immature, and not the right level of abstraction. Given some application servers, like Tomcat and Wildfly (formerly JBoss) still exist today, calling them a failure may be a bit strong, but their continued operation today should be compared to operating mainframes.
Virtualisation - the keystone of the cloud
The early 2000’s saw an increased interest in virtualisation through pioneers like VMWare (founded 1998). Being able to backup- and reproduce entire environments had become a problem.
In some cases, if server hardware would fail, it would mean the end of that system. This could be due to replacement hardware compatible with the software no longer being available, or simply because no one knew how a system was put together. I personally remember a project in the 2000s where a data centre was being decommissioned, but some old mainframe systems would have to be airlifted from Ireland to the UK, simply because the hardware that ran the software was no longer being manufactured.
One answer to this dilemma is of course virtualisation. But outside of being able to keep-alive, migrate or backup ancient systems, virtualisation also gave rise to some exciting new possibilities..
AWS enters - “pets vs cattle” and the Cloud is born
Amazon Web Services launched in March 2006 and with it, the cloud as we know it today.
AWS launched with 3 services that are still around today: S3 for storage, SQS for queueing and EC2 for compute. EC2 in 2006 was entirely stateless - persistent disk storage was not available, and once a machine crashed or was taken down, everything with it was gone. If you wanted repeatability, you had to build an Amazon Machine Image, a pre-built Virtual Machine specific to AWS.
The benefits of AWS cloud offering far outweighed its limitations. A typical disruptive technology in the mould described by Clayton Christensen, it was good enough, while allowing companies to shift from up-front capital expenditure to ongoing, predictable operational expenditure. This in turn gave rise to much of the technology boom we have seen since 2006, as startups could now afford infrastructure they could never afford just a few years earlier.
The restrictions of AWS EC2 gave just the right set of incentives for industry and customers to finally adopt virtualisation on a grand scale.
This required a firm shift of mindset from “pets to cattle”:
In the past, sysadmins were often allowed to organically grow their configurations and servers over time. The conscious limitations of Infrastructure as a Service made this approach far less practical. Of course, the approach of “snowflake servers” always held great operational risk: what happens when a “pet” server dies? What is the time to resumption of service? The Cloud laid bare the inherent risks of prior practices. At the same time, the ability to spin up new environments on demand greatly reduced the constraining factor of never quite having enough environments to test software in production-like environments, thus further reducing the risk of change.
AWS opened the floodgates to the age of IT operations automation, and the slow, but certain adoption of DevOps practices. The cloud also shifted the cost of infrastructure from large up-front capital expenditure to more easily predictable operational expenditure.
Docker gets packaging right
Building Amazon Machine Images was not initially trivial, and it was a proprietary format. Likewise, VMWare and its competitors had formats for pre-packaging virtual machines, but they often involved setting up the entire image by hand first, before being able to package it. Furthermore, the performance overhead of virtual machines is not negligible, therefore, they are still likely to be treated like “machines” in their own right, rather than application bundles.
Enter Docker. Docker has provided us with a few benefits compared to prior technologies:
- Packaging defined as code: no need to pre-build an entire environment, just produce from the Dockerfile in seconds or minutes.
- Lower overhead compared to VMs: Docker uses namespaces & cgroups for process isolation, thus providing a secure, but lower overhead for virtualisation.
- Everything in one package: compared to J2EE and other application packaging technologies, being able to package everything, including other software a package may rely on, is a great step forward, providing holistic packaging of software.
Where virtualisation was a pre-requisite of the cloud, the combination of the cloud and predictable packaging finally meant that the foundational ideas of application servers could be dusted off and implemented meaningfully under a new name.
From Mesos & Swarm to Kubernetes - the rise of orchestration
We have arrived at a point, sometime around 2013-14, when we finally have infrastructure on demand, virtualisation and application packaging to make effective use of this, but the cost savings promised are not always delivered. Why?
Because we are still allocating infrastructure inefficiently.
Enter orchestration. Apache Mesos and Docker Swarm were early pretenders in the category, but have all but been overrun by the clear winner: Kubernetes.
Orchestration allows us to abstract away from the underlying infrastructure: we no longer have to worry about which servers are running which VMs and how they are interconnected. Just let the orchestrator take care of it. An orchestrator can also efficiently assign and reassign workloads, so that existing resources are effectively used. The eagle-eyed might note a parallel to the time-scheduling of the punch-card and mainframe era. It’s not a bad parallel to make, technologies change, but fundamental ideas remain.
Taking orchestration and scheduling one step further in a cloud environment, the use of auto-scaling can also elastically add- or remove underlying servers, as well as monitor their health, thus removing a large amount of operational effort. With the advent of services like Google Kubernetes Engine & AWS Fargate, the case for on-premise hosting is looking increasingly thin. Furthermore, investing operational effort in areas that Google or AWS automate away looks foolish: who is likely better at it, Google & Amazon, or an organisation who is not in the business of Platform-as-a-Service?
In summary, container orchestration allows us to:
- Reduce operational costs by more effectively assigning, using, increasing and reducing the resources required.
- Reduce the scope of everyday IT operations work.
- Improve speed- and productivity of software delivery through automation (true Infrastructure-as-code).
Serverless & Function as a Service
The next step in the evolution of infrastructure is Serverless. It takes orchestration to its ultimate end, completely removing the need to know about the underlying infrastructure.
The cost efficiency is further increased: services that are not used, often cost a grand total of $0. There are no idle servers or resources anywhere to pay for. Variable workloads are also better handled: what if you have something which is idle on weekends, evenings and nights, but needs to deal with very high loads say on Monday mornings and Friday evenings? Serverless will handle this for you automatically, without you having to worry about the sizing of an underlying cluster.
Serverless also further reduces the administrative and operational burden, allowing more time to be spent on developing software and less time spent on operating it. It does however not mean that there is no overhead at all: serverless often requires equal, if not greater discipline in automation.
When people think of Serverless, they naturally think of AWS Lambda. But there is more. AWS offering is perhaps the most mature implementation of Serverless, but Googles Cloud Run & Cloud Functions are fast catching up. Meanwhile, Open Source initiatives like Knative (the underlying technology for Cloud Run) are also popping up, ensuring you don’t need to be locked into a specific vendor.
What is the future: Orchestration or Serverless?
We believe that orchestration and Serverless will co-exist side-by-side in the future. Serverless has significant benefits over orchestration, but may not be suitable in all cases. For instance, latency sensitive systems, or systems which have heavy sustained loads may be better built on top of Kubernetes rather than Serverless. But for many other types of systems, we would lean towards Serverless. On the other hand, the distinction between orchestration and serverless is not always clear-cut. We expect this line to be further blurred in the future, to the point were it will be hard to make a clear distinction.
We will definitely return to the relative trade-offs and choices between Serverless and orchestration in a future post, so please feel free to sign up to our email list to get notified.
End note
This article summarizes a vast time period of computing. It is a subject that deserves its own book. For that reason, it will omit large parts of history and miss out on significant details.