A Dive into Data Mesh and Data Fabric
The volume of data generated by companies has increased exponentially. At the same time, the need for faster feedback and realtime analytics has exploded. Organisations striving to maintain a competitive edge must adjust their data practices accordingly. Traditional data management architectures and organisational structures frequently fail to meet these new demands.
It is within this new environment that concepts like Data Mesh and Data Fabric have emerged. Each proposes a different approach to the challenges faced by conventional systems. The discourse around these paradigms is not merely academic. It informs us how enterprises can unlock the transformative potential of data.
The Old Status Quo
New techniques and ways of working don’t appear in isolation. Before we get into Data Mesh, we need to understand how companies have previously taken care of data management.
In the early days, Data warehouses were the main platform for data analytics and BI reporting. With the drastic increase in data volume and data types that came later, the concept of a Data lake appeared. The latest spin on that was the creation of Data Lakehouses. No one said marketing terms have to be original.
The main difference between these structures is one of technical implementation details. How they consume diverse data sources, how they handle schemas, how they provide access to the data.
The common factor is that they all belong to the Data team. A central data team in the organisation, with data analysts, engineers, and others. This team handles most of the requests to access data, and to consume new data sources.
Naturally, as the demand for data access increases, this creates a bottleneck. Requests go into the backlog, and they are not fulfilled within reasonable timeframes. Not only that, by having a centralised location for data pipelines, any outage impacts all teams at once.
It is said that Data is the new Oil. The centralised Data team was a bottleneck that made exploitation of data difficult. Companies need an alternative way to handle data access and to solve the various issues related to the centralised Data team.
Defining Data Mesh
Data Mesh is a term coined in 2019 by Zhamak Dehghani to define new practices for managing analytical data. Data Mesh is a paradigm shift in big data management toward data decentralization.
She coined the term as a way to showcase the transition from data-warehouses and data-lakes towards a more scalable model. A very simplified way of looking at it would be to consider microservices, very popular at the time. With a microservices’ architecture, teams organise around a business domain. They become experts of that domain and create infrastructure and services as required.
Why not do the same with data? Why is it necessary for them to seek the assistance of a central data team, rather than handling their data requirements? After all, they know more about the domain, and its data.
In a more formalised way, a Data Mesh is built on top of four core concepts:
- Domain-oriented decentralised data ownership and architecture.
- Treating data as a product.
- Self-serve data infrastructure as a platform.
- Federated computational governance.
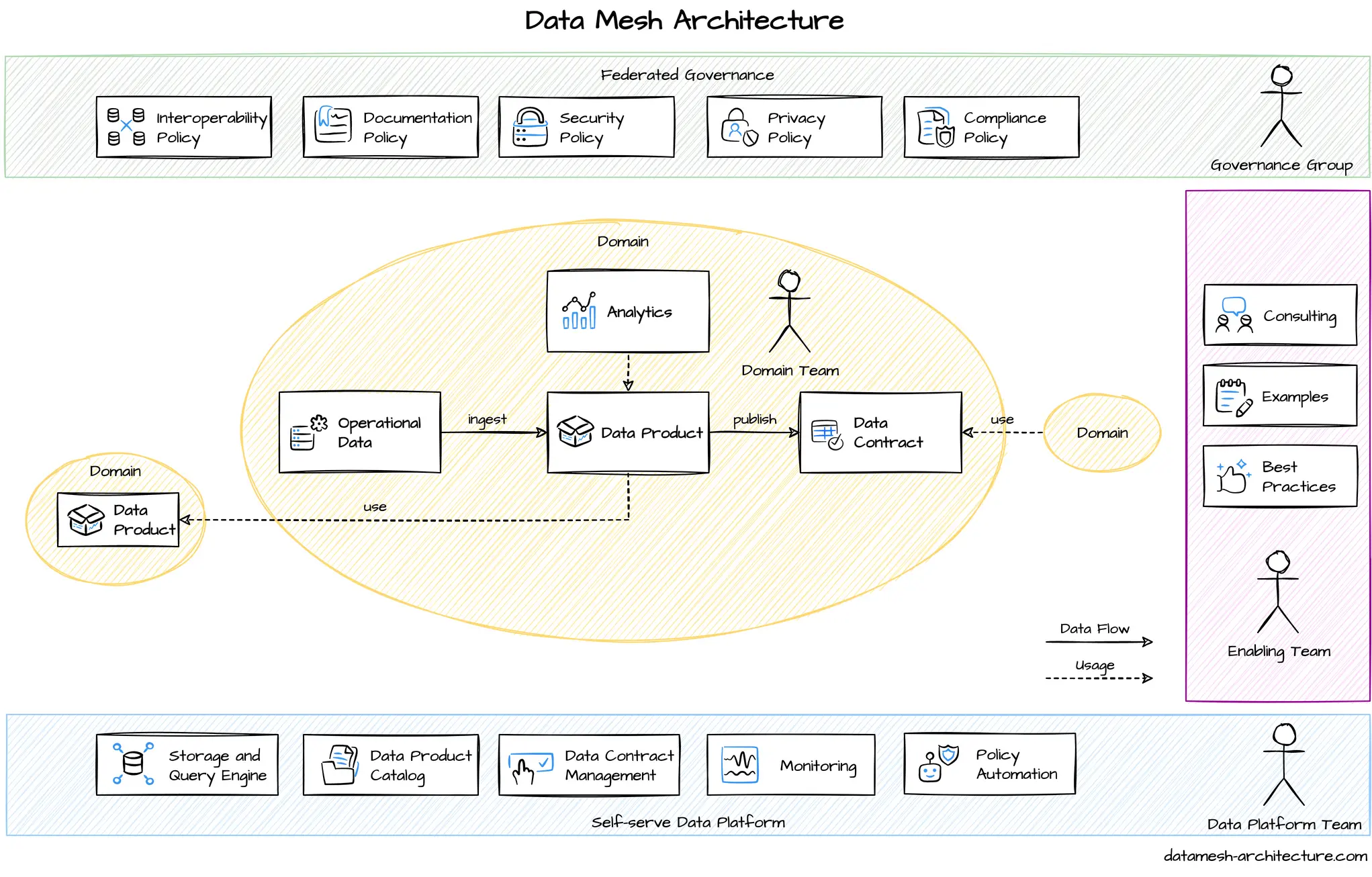
Decentralised Data Ownership
The core concept behind a Data Mesh is simple: decentralise and distribute the responsibility over the data to the people who are closest to it.
Organisations create teams that handle specific areas of the business domain. There is no reason why they can’t own the data within their domain’s bounded context.
People in charge of a domain oversee the collection of data, processing, and all the steps up to serving a data product.
Data as a Product
The team responsible for a domain creates a product. You can see that product as a new service that takes care of the data-needs of other teams. Any internal or external request for data should be answerable by this service.
This product is not only the output (data and metadata exposed to other teams), but includes the infrastructure and code required for this. It may have ETL, S3 buckets, Ansible play books, and more.
The product created by the team has to be useful to the organisation. To that end, a contract exists between producer and consumer. This is like contracts between front-end and backend endpoints in non-data domains. The contract may include the endpoints available, the schema, SLAs for the service, and even billing details.
This ensures the product provides access to the relevant data, without having to expose internals to the organisation. The team is free to build the product as they wish, as long as they are compliant.
Self-service Platform
Having each team manage their data is good, but it could cause duplication of work on infrastructure. To reduce that, a centralised data platform team provides a common abstraction that the other teams can build upon.
Given we mentioned a centralised team, we have to clarify. This team doesn’t handle data, only the infrastructure related to data. It can, for example, provide and maintain a Spark cluster. But the individual teams are still in charge of feeding data and jobs to the cluster. The platform team just simplifies operations.
Federated Governance
As with microservice architectures, we need a set of common rules for our separate data teams. We already provide a common platform for them. But there are rules we want to enforce company-wide, for example the formats allowed for communication, or versioning policies.
This governance is not aimed at reducing the independence of teams. The governance team should include all the existing teams involved in the data mesh. They define global policies, needed for interoperability or compliance reasons. There may also be custom policies for specific domains in the organisation.
But it is also important to note what they don’t define. They don’t set rules on how teams work with data. They don’t prescribe tools (except recommend the data platform). This is essential, as restricting the autonomy of teams would bring back the issues we had with centralised data teams.
The Dangers with Data Mesh
As it often happens, the theory behind Data Mesh is clear, but the implementation is not always simple. Many implementations fail or are abandoned after a brief period, reverting to the old ways of working. It is essential to understand why, to avoid making the same mistakes.
A Cultural Change
The main reason adoption of a Data Mesh fails is a misunderstanding of the concept. Although it is tightly coupled with technology, a Data Mesh is, at its core, a cultural change in the company.
This means that deploying a shared platform and telling people to start using it is not enough. A bad adoption can go the way of many Agile transformations in the past decade. Teams adopt the rituals, and mechanically check the boxes. But they don’t understand the motivation behind the practices, and reap no benefit from the change.
Another big risk with the transition is resistance to change, specially by the central data team. An unfortunate reality of organisations is that centralised teams accrue power. The centralised data team is no exception, and fragmenting that team means that many people will need to change roles. Teams will stop being on the critical path of all major decisions.
This may seem minor. But we have seen, in the past, transformations to DevOps fail due to the central system administrator’s team opposing the change. Beware of this issue, no one expects overt sabotage, but partial implementations to appease the teams can be worse than keeping the old way.
Slow time to ROI
Another common concern coming from management is the pace of adoption and the expected ROI. We live in a world where organisations frequently focus on the short term. Quarterly results are the old annual reports, more so for publicly traded companies. Any change must provide a benefit, and soon.
This is the reason many transformations, be it Agile, Digital, or Data Mesh, flounder. As we discussed, the core change is not technical, but social. Company-wide practices and rituals used for many years have to change. Organisations may not have the patience for it. Often, they stop the initiative (dropped from budget allocation in the next quarter). Or, worse, they settle on a half-done implementation under the expectation that it provides some benefit.
But a partial implementation is keeping the problems of the old way of working and adding the issues of the new way of working, with none of the benefits.
It is important to understand that a Data Mesh is not a tactical change, but a strategic one. It creates a foundation for future growth, and it is a clear competitive advantage over companies that don’t have it.
Even more, adopting Data Mesh is proof that the organisation can address organisational change. The company can manage cultural shifts. And this means it is ready to adopt the new techniques that, no doubt, will appear in the coming years.
What about Data Fabric?
Recently, another term appeared: Data Fabric. But there seems to be a lack of clarity around it, and how it relates to Data Mesh. Let’s elaborate on it.
Gartner defined Data Fabric in 2021, 2 years after Data Mesh appearance as a concept. They say that it is “a unified enterprise architecture underpinned by an integrated set of data platforms, technologies and services, designed to deliver the right data to the right data customer at the right time”.
We can agree this is a very Gartner definition. To make it more clear, the idea of a Data Fabric is largely focused on a collection of technical tools. These tools combine to produce an interface for the end-users that consume data.
To reiterate, Data Fabric starts from the technical elements, the building blocks of the data infrastructure. It tries to create a unified management framework through those tools.
Moreover, Data Fabric tries to leverage automation. For example, it may integrate ML to recognise changes to the data received. Then it can automatically create new reports that highlight those differences. The idea is to use AI and ML to reduce the dependency on data analysts and data experts.
Data Mesh versus Data Fabric
Both Data Mesh and Data Fabric aim to improve over traditional data management architectures. Where they diverge is in philosophy and implementation.
The idea of a Data Fabric focuses on the collection of technical tools. These tools combine to produce an interface for the end-users that consume data.
Proponents of Data Fabric also highlight other benefits:
— Unified View: Data Fabric facilitates a unified view of data across the organisation. This is instrumental in eradicating silos and a more profound understanding of data.
— Streamlined Access: With a consistent framework for data access, Data Fabric accelerates data flows.
— Enhanced Compliance: Data Fabric can significantly simplify compliance with regulatory requirements.
In a sense, a Data Fabric could be part of a Data Mesh. But it could also be a part of the old way of working, with a centralised team.
A Data Mesh takes things further. Data Mesh acknowledges the organisational changes needed for success. With the four pillars it defines, it ensures impact across the enterprise. It makes sure business users can access the data and get involved in data-driven decisions. It builds a data-driven culture.
A Reaction to Failure
A Data Fabric also has an emphasis on automation. But the automation capabilities it proposes are something teams in a Data Mesh can adopt. It’s not exclusive. By itself, it doesn’t justify this trend.
There is another argument the proponents of Data Fabric use for its adoption: breaking the silos. Data Fabric wants to unify access to all data repositories. To make sure all data is available. This centralised approach comes with certain risks that Data Mesh tried to remove.
Given that, we understand the appearance of Data Fabric as a reaction to failed Data Mesh implementations. A badly implemented Data Mesh will create data silos that are hard to access by other teams. It may hinder data-driven decisions. It is a natural reaction, more so by upper management, to try to reassert control by centralising things again.
To be clear, we are not saying a Data Fabric is always bad. But, as Data Mesh adoptions fail, so can Data Fabric adoptions. A centralised platform makes is far too easy to revert, step by step, back to the older operating model. Arguments on cost-savings and on duplication remove power from the teams. Inertia towards tradition may turn a Data Fabric into a trap, restricting innovation and adoption of newer practices. The over-arching risk here is to seek technical solutions to cultural- and social problems.
Opting for Data Mesh or Data Fabric
When you have related concepts, it is unavoidable to see them as a choice. Should your organisation bet on Data Fabric or on Data Mesh? Which one is better?
In this case, we believe this is the wrong way to think about it. Data Mesh and Data Fabric can coexist and, in fact, they complement each other.
We see a Data Mesh as the core of the transformation. The organisational changes and new practices are good, not just for data management. If you want to pick one, pick this one. Long term, it will bring the most benefit.
But a properly implemented Data Fabric is a great tool. We don’t see a Data Fabric as an independent implementation. It could be part of the technical infrastructure that supports the Data Mesh.
Conclusions
The discourse on Data Mesh and Data Fabric isn’t a binary narrative. Rather, it reflects the continuum of data architecture evolution in modern-day enterprises. The choice between these paradigms isn’t a matter of right or wrong, it doesn’t need to a choice at all. A company can adopt both.
Data Mesh, with its decentralised ethos, enhances not only data processing, but moves an organisation towards more effective ways of working. Companies managing this shift successfully are more ready to adopt future innovation. Not only because of the Data Mesh, but because of the culture they foster.
Conversely, Data Fabric provides a harmonised data tooling landscape and simplifies compliance.
Both are considerable changes with associated risks. Data Mesh can fail in the face of an immobile culture and power silos. Data Fabric, if mismanaged, can become a new centralised bottleneck.
With a careful strategy for adoption, both are parts of the puzzle to unlock the transformative potential of data.